- All of Microsoft

Integrate Personal Data into LLM with Azure AI Search in AI
Create JohnBot with Azure AI: Tailor LLMs to personal data for smart, customized chat experiences!
Using your own data with large language models (LLMs) can be quite beneficial for customized AI applications. In a constructive YouTube video, John Savill showcases the process of incorporating personal data with LLMs, specifically using GPT and Azure AI Search. To give a practical demonstration, he creates an example called JohnBot.
The video is structured with various timestamps, starting with an introduction and explaining the need for utilizing our own data. It progresses to describe sourcing the data, using Azure AI Search for integration and reading data, and delves into indexing such data. Savill also addresses the importance of appropriate interval selection for data import, and demonstrates the viewing of the index and indexer.
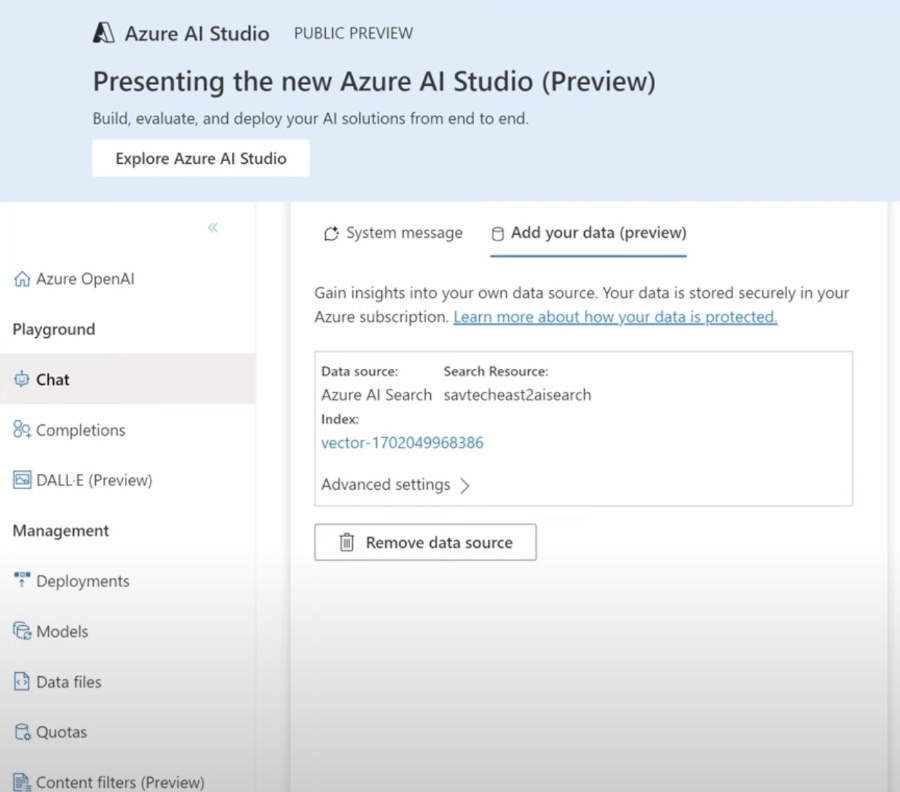
Azure AI Search in AI + Machine Learning
Azure AI Search is a powerful tool for developing robust AI and Machine Learning applications. It supports both Semantic Search for improved text-based searches and in-preview Vector Search for contextually relevant results. The technology, which evolved from the advancements made by Microsoft's Bing and Research teams, offers new possibilities in personalizing search experiences and fine-tuning data relevance. As AI continues to advance, these tools are becoming increasingly essential in building sophisticated and intelligent applications designed to understand and anticipate user needs effectively.
Understanding Custom Data Ingestion for Large Language AI Models
This video explores the potential of feeding custom data into Large Language Models (LLMs) like GPT, using Azure AI Search. It showcases the creation of a custom bot, named JohnBot, to demonstrate the practical application of these concepts.
The tutorial walks viewers through the process, emphasizing the necessity of incorporating proprietary data into LLMs for enhanced personalization and relevance in search results.
Key timestamps in the video include an introduction to the topic, the importance of custom data, and step-by-step guidance on using Azure AI Search for data integration and indexing.
Digging Deeper into Azure AI Search and Machine Learning Capabilities
The article that follows the video discusses how to further exploit Azure Cognitive Search's capabilities for AI and Machine Learning tasks, highlighting Semantic and Vector Search functionalities currently in preview. Azure Cognitive Search, previously known as Azure Search, provides robust infrastructure and tools for a rich search experience across various applications.
Semantic and Vector Search are distinguished as key features for LLM-powered applications, providing advanced document retrieval based on user queries in natural language, although they operate differently.
A more detailed examination reveals the benefits and limitations of both search methodologies, including the ease of integration and managed services offered by Azure Cognitive Search.
Advantages and Challenges of Semantic and Vector Search
Semantic Search, rooted in technologies from Bing and Microsoft Research, improves search results through BM25 ranking and subsequent AI-based semantic reranking. It offers enhanced search experiences with useful captions and answers, serving as a user-friendly feature in Cognitive Search.
Despite its ease of integration, Semantic Search's reliance on BM25 could overlook important factors like document structure and relevance feedback, which Vector Search addresses differently.
Vector Search, on the other hand, translates items into numerical vectors and employs cosine similarity, among other operations, to determine item similarities. This method is especially useful for AI applications as it helps in retrieving contextually relevant documents through an intelligent search arrangement.
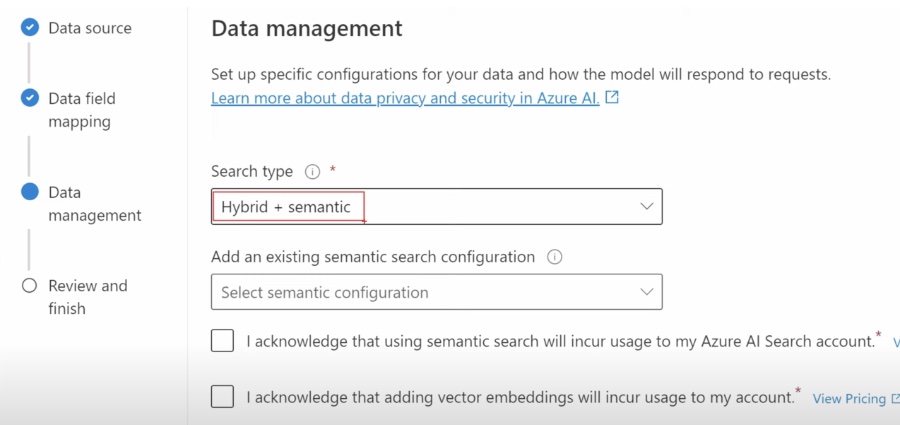
Implementation and Considerations for Vector Search
To implement Vector Search, text must be converted into vector representations and stored in an index, with the process requiring additional steps compared to Semantic Search. Azure Cognitive Search does not offer a vector encoder, hence external preprocessing is needed.
The upcoming sections will present a guide on developing an application similar to ChatGPT utilizing Vector Search in Azure Cognitive Search and will offer a comparative analysis between the two search types, as the platform offers both as managed services.
While Vector Search promises more accurate context-relevant results fitting well within the landscape of AI + Machine Learning, it introduces complexities like the need for document chunking and data embedding.
- 00:00 - Introduction to video and topics
- 00:26 - Necessity of using custom data
- 02:14 - Details about source data
- 05:37 - Using Azure AI Search for data integration
- 08:19 - Process of data reading and integration
- 11:24 - Guidelines on importing and indexing data
- 13:38 - Deciding on the right indexing interval
- 16:18 - How to view the indexed data
- 18:11 - The concept of chunking data
- 24:51 - Incorporating different media types beyond text
- 25:32 - Reminder on the key takeaway
- 29:43 - Continued relevance of keyword search
- 32:41 - BM25 searching mechanics
- 34:15 - Combining search methods for hybrid functionality
- 41:27 - Introduction of the orchestrator component
- 43:30 - Utilizing the Playground for key settings management
- 44:20 - Adding a data source for the model
- 47:05 - Demonstrating an interaction with JohnBot
- 50:20 - Examining the response and sourcing references
- 55:12 - A summary of points covered
- 56:55 - Concluding remarks
Exploring AI + Machine Learning in Search
In the realm of AI and cognitive technologies, search capabilities are incredibly enhanced through the integration of custom, proprietary data. By employing Azure Cognitive Search's advanced features, such as Semantic Search and Vector Search, developers can craft intuitive and contextually relevant search experiences. These technologies facilitate not just typical keyword retrieval but a nuanced understanding and response to user queries. They leverage the power of AI, including Machine Learning and advanced algorithms, to revolutionize the way we interact with data, making the search experience not just more efficient, but also more intelligent.

People also ask
Can I train my own LLM?
Yes, it's possible to train your own large language model (LLM), though it requires significant computational resources, expertise in machine learning, and access to a large corpora of text data to train on. Individuals or organizations typically leverage cloud computing platforms, such as Microsoft Azure, to manage the computational load and storage required for such an endeavor.
What is a large language model (LLM)?
A large language model is a type of artificial intelligence model that has been trained on vast amounts of text data. It utilizes deep learning algorithms, typically transformers, to understand and generate human-like text. LLMs are designed to perform a variety of natural language processing tasks, such as translation, summarization, question-answering, and content creation.
Can you make your own large language model?
Yes, it is technically possible to create your own large language model if you have the necessary resources and technical skill set. This entails setting up the proper infrastructure for training a model, which involves choosing and configuring machine learning frameworks, obtaining a sufficiently large and diverse training dataset, and having the processing power necessary to train the model.
How do I make an LLM model from scratch?
To make an LLM model from scratch, you need to follow these steps: 1. Acquire a large and diverse dataset suited for the linguistic tasks you want the LLM to learn. The dataset should consist of high-quality text in the desired language(s). 2. Choose a machine learning framework and architecture (e.g., TensorFlow with a transformer architecture). 3. Preprocess the data to be suitable for training, which may include tokenization and normalization. 4. Define and setup the model topology based on the desired size and complexity of the LLM. 5. Execute the training process, which can take a considerable amount of time and computational power to run through many epochs over the large dataset. 6. Evaluate the model’s performance and fine-tune hyperparameters as necessary. 7. After training, the model can be further fine-tuned for specific tasks or datasets.
Keywords
personalized LLMs, custom data integration, JohnBot creation, training language models, language processing techniques, bespoke AI development, LLM data usage, LLM customization, user-specific LLM training, tailor-made language models