- All of Microsoft

Optimize Data Sources in Deployment Pipelines 2024
Master Power BI Deployment Pipelines and Update Data Sources Seamlessly!
Key insights
- Understanding Deployment Pipelines in Microsoft Fabric: The text provides essential guidelines on updating data sources for Power BI sematic models and emphasises the progressive stages involved in a deployment pipeline within Microsoft Fabric.
- Guided Process: Step-by-step instructions are given to create and manage deployment pipelines, ensuring clear understanding and execution, from setting up, defining the structure, to deploying content across stages.
- Workspace Configuration: A crucial aspect discussed is the assignment of Premium workspaces to different pipeline stages and the specific configurations for stages that involve varying queries and databases.
- Deployment Options: The pipeline provides flexibility in deployment strategies, offering full deployment where all content is moved to the next stage or selective deployment for specific content, tailored to the needs of the user.
- Advanced Features: Additional functionalities such as making stages public and creating deployment rules for content are detailed, allowing users to handle various scenarios and requirements effectively.
About Deployment Pipelines in Business Intelligence
Introduction to Deployment Pipelines
Adam from the YouTube channel "Guy in a Cube" explains the role of Deployment Pipelines in Microsoft Fabric, specifically for Power BI semantic models. Deployment pipelines are essential tools allowing users to manage, stage, and update data sources efficiently as they scale applications across various stages. This includes moving developments from Testing to Production environments smoothly and systematically.
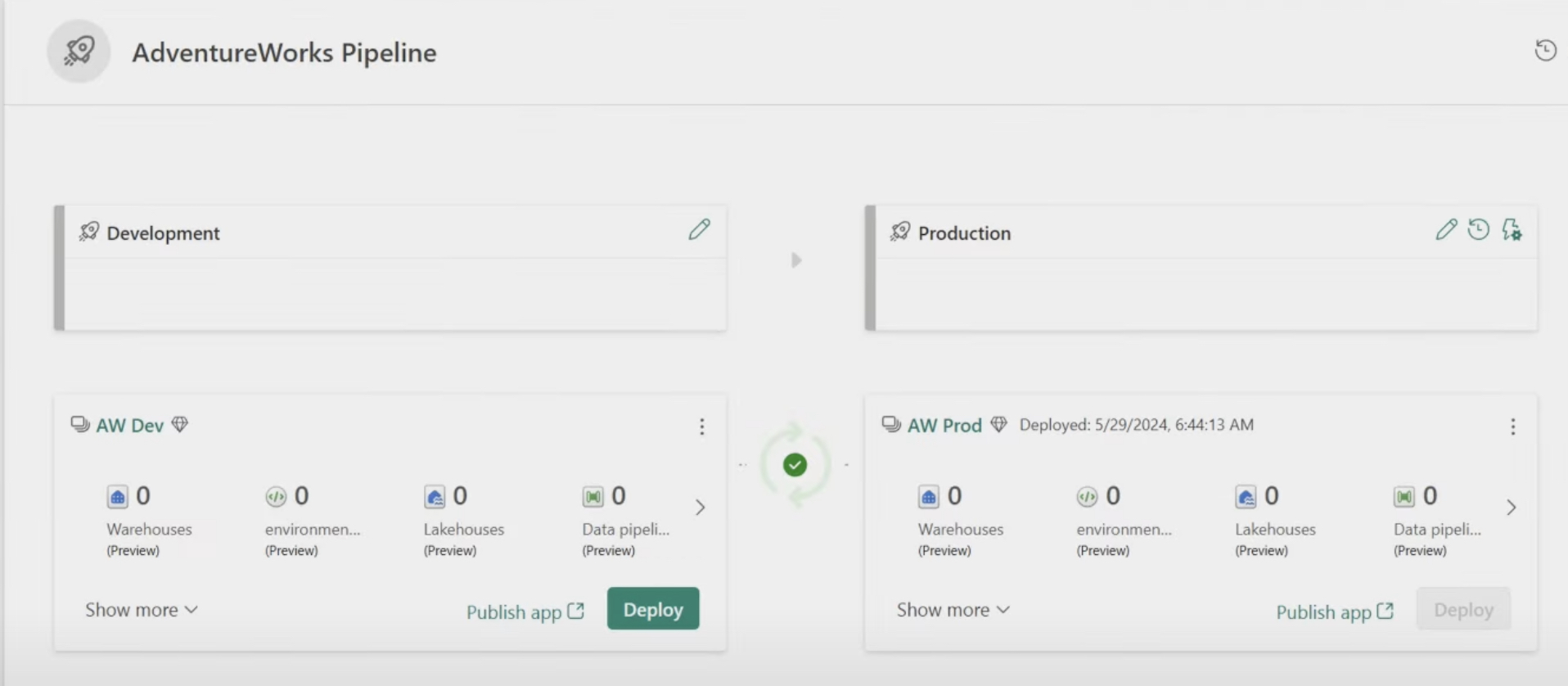
Getting started with deployment pipelines requires a Microsoft Fabric subscription and admin access to a Fabric workspace. Initially, a deployment pipeline is set with three standard stages - Development, Test, and Production. Users have the flexibility to modify these stages by adding, deleting, or renaming them. The creation of pipelines can be initiated from a general Fabric workspace or directly through specialized deployment pipelines entries.
Step-by-Step Pipeline Management
Creating a pipeline is user-friendly; you start by naming and describing your pipeline before defining the stages needed for your development process. The dialog box provides options to manage the sequence and names of each stage.
Once a pipeline is crafted, the next step involves assigning a workspace to a stage within the pipeline. This is essential for moving and managing content across different stages. If the pipeline is established from an existing workspace, this stage is automatically covered.
Deployment options vary, allowing full deployment, where all content is moved to the next stage, or selective deployment, where only specified content is transferred. Each stage movement can be deployed with an overview and accompanying notes for clarity.
Advanced Pipeline Features and Customization
Deployment rules feature significantly in customizing data flow within pipeline stages. For instance, a development stage might handle sample data, while production stages handle more comprehensive datasets. Deployment rules facilitate these varied data handling needs by allowing users to specify how data should be treated as it moves through the pipeline.
For higher flexibility, stages can be set to public or remain private based on the organization's visibility needs. This flexibility assists in controlling how different pipeline stages interact with broader audience or confined teams.
Finalizing the pipeline process involves reviewing differences between stages before deploying, ensuring that each stage aligns correctly with the sequential needs of the development and deployment process.
Conclusion and Further Reading
In the intricate web of modern data handling and business intelligence, Microsoft Fabric's Deployment Pipelines serve as crucial Developer Tools. They not only streamline the migration of projects through various development stages but also ensure that each stage is optimally configured to the specific needs of the business. For additional information or to troubleshoot deployment pipelines, resources and detailed guidelines are available directly through Microsoft Fabric, Developer Tools, and Microsoft Purview.
Expanding on Deployment Pipelines
Deployment Pipelines in Microsoft Fabric represent a sophisticated toolset designed to assist developers and IT professionals in the efficient management of application lifecycles. They allow meticulous control over the development, testing, and production stages of software products, particularly those integrated with Power BI and other data-centric applications. Effective use of these pipelines ensures that updates and changes are seamlessly propagated across different stages without disrupting the overall functionality.
Moreover, the role of Deployment Pilications is pivotal in modern business environments where data-driven decisions are paramount. They support the dynamic needs of businesses by ensuring data consistency across different operational stages, thereby minimizing errors and enhancing reliability. The ability to customize stages and define specific deployment rules allows organizations to tailor their development process to meet precise business requirements.
Ultimately, embracing Deployment Pipelines in project management and operations translates into more robust, efficient, and error-free deployments. This ensures that enterprises can leverage the maximum potential of their data handling and analytics capabilities, driving better business outcomes and enhanced operational efficiency.

People also ask
What are the four main stages of a deployment pipeline?
We will explore the fundamental phases of a deployment pipeline and their roles in software development. The Commit stage marks the beginning of the pipeline, activated by code submissions to a version control system (VCS). Following this, the Automated Testing stage ensures the robustness of the code through systematic checks. Subsequently, the Staging Deployment phase serves as a pre-production testing ground, and finally, the Production Deployment stage, where the software goes live.
What are the three stages supported by deployment pipelines?
The structure of deployment pipelines encompasses three main stages. The Development stage, which is the inception point where new content is integrated. Following the development cycle, the Test stage allows for rigorous validation of modifications. Conclusively, the Production stage represents the endpoint where content goes live and operational.
What are some common driving goals for building a deployment pipeline?
The overarching objective in constructing a deployment pipeline is to obviate the need for manual processes. This entails developing customized solutions for the automatic compilation or building, testing, and deployment of new code starting from the development stage.
What are the components of deployment pipeline?
Typically, a deployment pipeline includes pivotal components such as Build automation or continuous integration, Test automation, and Deployment automation, each contributing to a streamlined and efficient deployment process.
Keywords
Update Data Sources, Deployment Pipelines, Data Source Management, Deployment Pipeline Optimization, Manage Data Sources, Data Pipeline Integration, Data Source Updates, Automate Data Pipelines